Python 공부하기
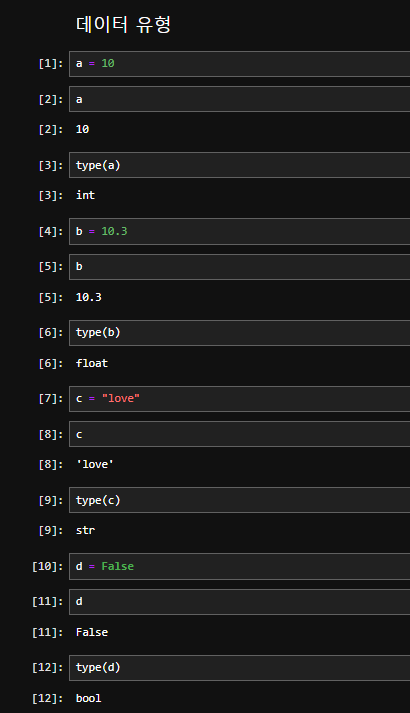
데이터 유형
테이터 구조
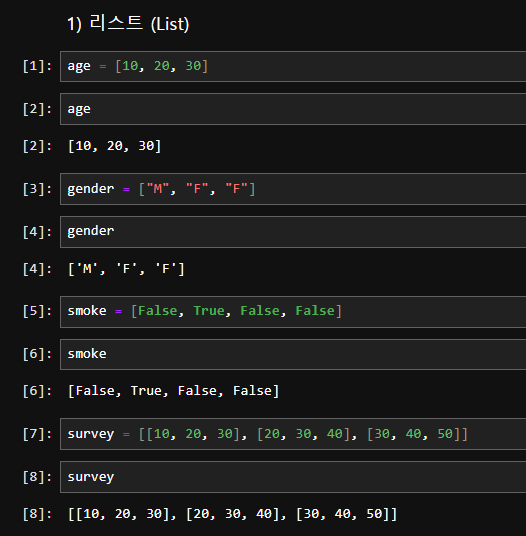
1. 리스트 (list)
2. 튜플 (tuple)
3. 딕셔너리 (dictionary)
4. 시리즈 (Series)
5. 데이터프레임 (DataFrame)
Python에서 데이터 유형(data type)은 변수에 저장할 수 있는 데이터의 종류를 정의합니다. Python은 여러 가지 기본 데이터 유형을 제공합니다. 다음은 주요 데이터 유형들입니다.
- 숫자형(Numeric Types):
- 정수형(int): 정수를 나타냅니다.
pythonx = 10y = -5
- 실수형(float): 부동 소수점 숫자를 나타냅니다.
pythonx = 10.5y = -2.3
- 복소수형(complex): 복소수를 나타냅니다.
pythonx = 1 + 2jy = 3 - 4j
- 정수형(int): 정수를 나타냅니다.
- 문자열(String Type):
- 문자열은 문자들의 집합입니다.
pythonx = "Hello, World!"y = 'Python'
- 문자열은 문자들의 집합입니다.
- 불린형(Boolean Type):
- 불린형은 참(True)과 거짓(False)을 나타냅니다.
pythonx = Truey = False
- 불린형은 참(True)과 거짓(False)을 나타냅니다.
- 시퀀스형(Sequence Types):
- 리스트(list): 순서가 있는 변경 가능한 배열입니다.
pythonx = [1, 2, 3, "a", "b", "c"]
- 튜플(tuple): 순서가 있는 변경 불가능한 배열입니다.
pythonx = (1, 2, 3, "a", "b", "c")
- 레인지(range): 연속적인 숫자의 시퀀스입니다.
pythonx = range(5) # 0, 1, 2, 3, 4
- 리스트(list): 순서가 있는 변경 가능한 배열입니다.
- 매핑형(Mapping Type):
- 딕셔너리(dict): 키-값 쌍의 집합입니다.
pythonx = {"name": "Alice", "age": 25}
- 딕셔너리(dict): 키-값 쌍의 집합입니다.
- 집합형(Set Types):
- 집합(set): 순서가 없고 중복을 허용하지 않는 컬렉션입니다.
pythonx = {1, 2, 3, 4}
- 프로즌셋(frozenset): 변경 불가능한 집합입니다.
pythonx = frozenset([1, 2, 3, 4])
- 집합(set): 순서가 없고 중복을 허용하지 않는 컬렉션입니다.
- None Type:
- None: 값이 없음을 나타내는 특별한 데이터 유형입니다.
pythonx = None
- None: 값이 없음을 나타내는 특별한 데이터 유형입니다.
이러한 기본 데이터 유형들은 Python 프로그래밍에서 다양하게 사용되며, 각 유형마다 고유의 메서드와 속성이 있습니다. 이 외에도, Python은 다양한 라이브러리를 통해 사용자 정의 데이터 유형을 만들고 사용할 수 있습니다.
Python에서 리스트, 튜플, 딕셔너리, 시리즈, 데이터프레임은 각각 고유한 특징과 용도를 가진 데이터 구조입니다. 이들을 이해하고 사용하는 것은 데이터 처리와 분석에서 매우 중요합니다.
1. 리스트 (list)
- 정의: 순서가 있는 변경 가능한 배열입니다.
- 특징:
- 대괄호 []로 정의합니다.
- 다양한 데이터 유형을 포함할 수 있습니다.
- 요소를 추가, 삭제, 변경할 수 있습니다.
- 예시
리스트의 이름 = [ 값 1, 값 2 ]
my_list = [1, 2, 3, "a", "b", "c"]
my_list.append(4) # [1, 2, 3, "a", "b", "c", 4]
; [[ ], [ ]]
괄호 안에 있는 괄호 1행을 나타냄,
이는 2개의 행이 존재한다는 것. (2차원적인 생각...)
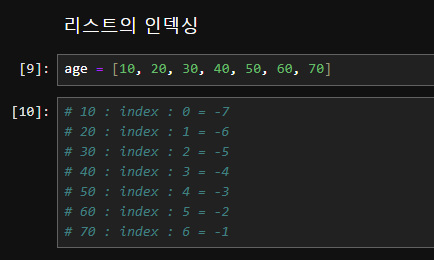
인덱스(index)와 음수 인덱스(negative index) ???
Python에서 리스트(list)는 순서가 있는 배열로, 각 요소는 인덱스를 통해 접근할 수 있습니다. 인덱스(index)와 음수 인덱스(negative index)는 리스트의 요소에 접근하는 두 가지 방법입니다.
인덱스 (Index)
- 정의: 리스트의 각 요소는 0부터 시작하는 정수형 인덱스를 가집니다. 인덱스를 사용하여 특정 위치에 있는 요소에 접근할 수 있습니다.
- 특징:
- 첫 번째 요소의 인덱스는 0입니다.
- 두 번째 요소의 인덱스는 1, 세 번째 요소의 인덱스는 2, ... 와 같이 증가합니다.
- 인덱스를 사용하여 요소를 가져오거나 변경할 수 있습니다.
- 예시:
my_list = [10, 20, 30, 40, 50]
print(my_list[0]) # 출력: 10 (첫 번째 요소)
print(my_list[2]) # 출력: 30 (세 번째 요소)
my_list[1] = 25 # 두 번째 요소를 25로 변경
print(my_list) # 출력: [10, 25, 30, 40, 50]
음수 인덱스 (Negative Index)
- 정의: 리스트의 끝에서부터 요소에 접근할 수 있는 방법입니다. 음수 인덱스는 -1부터 시작하여 뒤에서부터 요소에 접근합니다.
- 특징:
- 마지막 요소의 인덱스는 -1입니다.
- 뒤에서 두 번째 요소의 인덱스는 -2, 그 다음은 -3, ... 와 같이 감소합니다.
- 리스트의 끝에서부터 요소를 가져오거나 변경할 수 있습니다.
- 예시:
my_list = [10, 20, 30, 40, 50]
print(my_list[-1]) # 출력: 50 (마지막 요소)
print(my_list[-3]) # 출력: 30 (뒤에서 세 번째 요소)
my_list[-2] = 45 # 뒤에서 두 번째 요소를 45로 변경
print(my_list) # 출력: [10, 20, 30, 45, 50]
요약
- 인덱스는 리스트의 시작부터 순서대로 접근하는 방법입니다. 예를 들어, my_list[0]은 첫 번째 요소를 가리킵니다.
- 음수 인덱스는 리스트의 끝에서부터 역순으로 접근하는 방법입니다. 예를 들어, my_list[-1]은 마지막 요소를 가리킵니다.
이 두 가지 인덱싱 방법을 사용하면 리스트의 요소에 유연하게 접근할 수 있으며, 특정 위치의 데이터를 쉽게 가져오거나 변경할 수 있습니다.
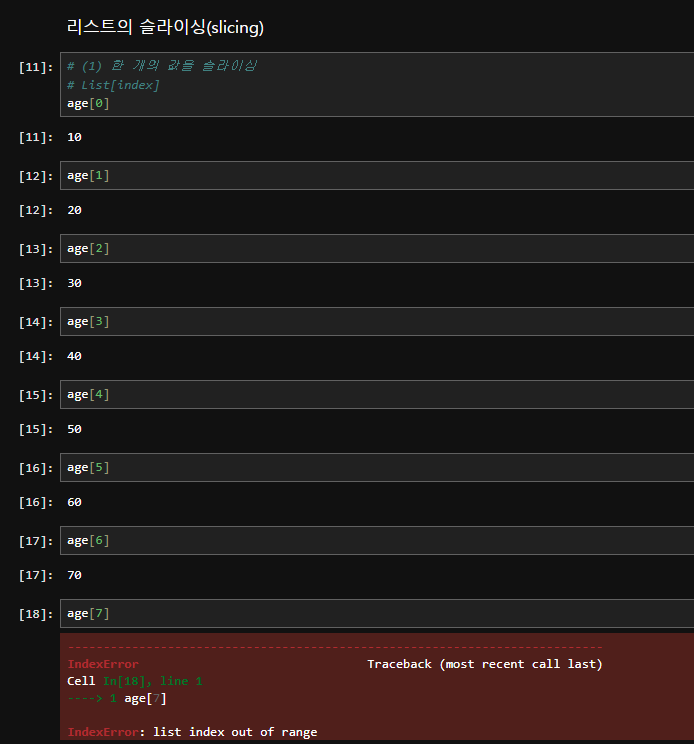
리스트(list)에서 슬라이싱(slicing)은 ???
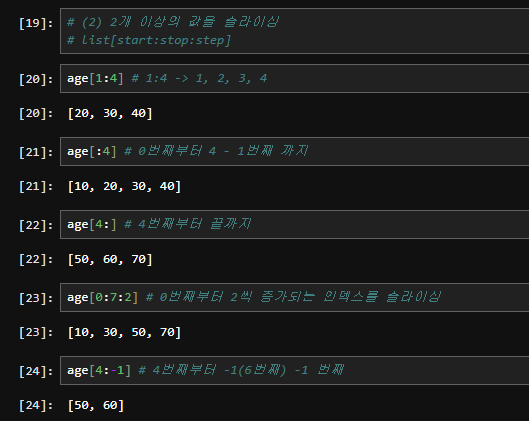
리스트(list)에서 슬라이싱(slicing)은 리스트의 특정 부분을 추출하여 새로운 리스트를 만드는 방법입니다. 슬라이싱을 사용하면 시작 인덱스와 끝 인덱스를 지정하여 원하는 부분을 쉽게 가져올 수 있습니다. 슬라이싱 문법은 list[start:stop:step] 형태를 사용합니다.
슬라이싱의 기본 문법
- start: 슬라이스의 시작 인덱스입니다. 이 인덱스의 요소는 포함됩니다. 생략하면 리스트의 처음부터 시작합니다.
- stop: 슬라이스의 끝 인덱스입니다. 이 인덱스의 요소는 포함되지 않습니다. 생략하면 리스트의 끝까지 포함합니다.
- step: 슬라이스를 진행할 간격입니다. 생략하면 기본값은 1입니다.
예시
다양한 슬라이싱 방법에 대한 예시를 살펴보겠습니다.
my_list = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
# 기본 슬라이싱: 시작과 끝 인덱스를 지정
print(my_list[2:5]) # 출력: [30, 40, 50]
# 시작 인덱스를 생략: 리스트의 처음부터 시작
print(my_list[:3]) # 출력: [10, 20, 30]
# 끝 인덱스를 생략: 리스트의 끝까지 포함
print(my_list[4:]) # 출력: [50, 60, 70, 80, 90, 100]
# 시작과 끝 인덱스를 생략: 리스트 전체
print(my_list[:]) # 출력: [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
# 음수 인덱스를 사용한 슬라이싱: 리스트의 끝에서부터
print(my_list[-5:-2]) # 출력: [60, 70, 80]
# 간격(step)을 지정한 슬라이싱
print(my_list[::2]) # 출력: [10, 30, 50, 70, 90] (2씩 증가)
print(my_list[1::2]) # 출력: [20, 40, 60, 80, 100] (1부터 시작해서 2씩 증가)
# 간격을 음수로 지정: 리스트를 거꾸로 슬라이싱
print(my_list[::-1]) # 출력: [100, 90, 80, 70, 60, 50, 40, 30, 20, 10]
슬라이싱을 사용한 리스트 수정
슬라이싱을 사용하면 리스트의 일부분을 수정할 수도 있습니다.
my_list = [1, 2, 3, 4, 5]
# 슬라이싱을 사용한 부분 수정
my_list[1:3] = [20, 30]
print(my_list) # 출력: [1, 20, 30, 4, 5]
# 슬라이싱을 사용한 부분 삭제
my_list[1:3] = []
print(my_list) # 출력: [1, 4, 5]
# 슬라이싱을 사용한 부분 삽입
my_list[1:1] = [10, 20, 30]
print(my_list) # 출력: [1, 10, 20, 30, 4, 5]
요약
슬라이싱은 리스트의 특정 부분을 추출하거나 수정할 때 매우 유용한 도구입니다. 시작 인덱스, 끝 인덱스, 간격을 지정하여 다양한 방식으로 리스트를 다룰 수 있습니다. 이 기능을 통해 리스트의 일부분을 손쉽게 접근하고 조작할 수 있습니다.
Python의 리스트(list)에서 사용할 수 있는 기본 연산은
Python의 리스트(list)에서 사용할 수 있는 기본 연산은 다음과 같습니다. 이 연산들을 사용하면 리스트를 생성하고, 수정하고, 결합하고, 반복하는 등의 작업을 수행할 수 있습니다.
리스트 생성 my_list = [1, 2, 3, 4, 5] *이 부분이 아래로 내려 갈수록 계속 수정되어짐
리스트는 대괄호 []를 사용하여 생성합니다.
리스트 요소 접근
인덱스를 사용하여 리스트의 특정 요소에 접근할 수 있습니다.
리스트 수정 my_list = [1, 2, 3, 4, 5]
인덱스를 사용하여 리스트의 요소를 수정할 수 있습니다.
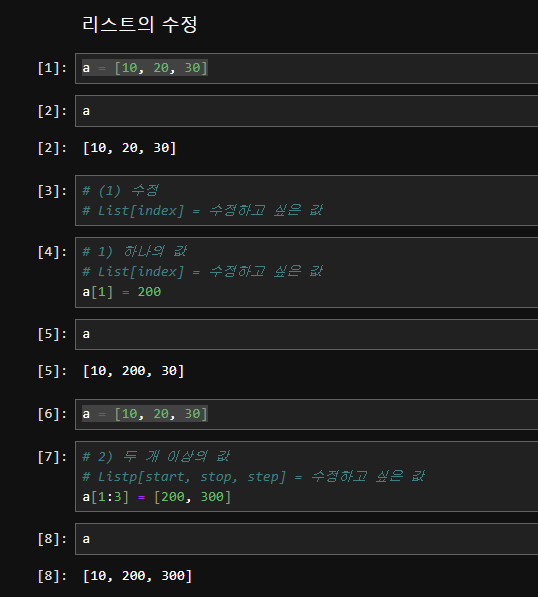
리스트 추가 my_list = [1, 20, 3, 4, 5]
append() 메서드를 사용하여 리스트의 끝에 요소를 추가할 수 있습니다.
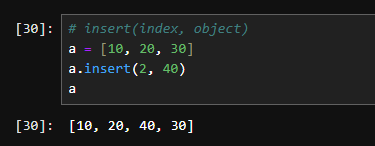
리스트 삽입 my_list = [1, 20, 3, 4, 5, 6]
insert() 메서드를 사용하여 특정 위치에 요소를 삽입할 수 있습니다.
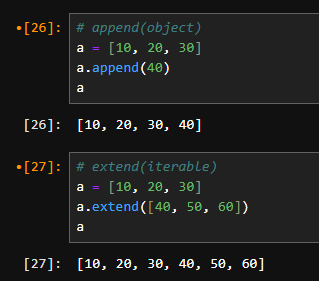
리스트 결합 my_list = [1, 15, 20, 3, 4, 5, 6]
extend() 메서드를 사용하여 다른 리스트의 요소를 추가할 수 있습니다.

또는 + 연산자를 사용하여 리스트를 결합할 수 있습니다.

리스트 반복 my_list = [1, 15, 20, 3, 4, 5, 6, 7, 8, 9]
* 연산자를 사용하여 리스트를 반복할 수 있습니다.

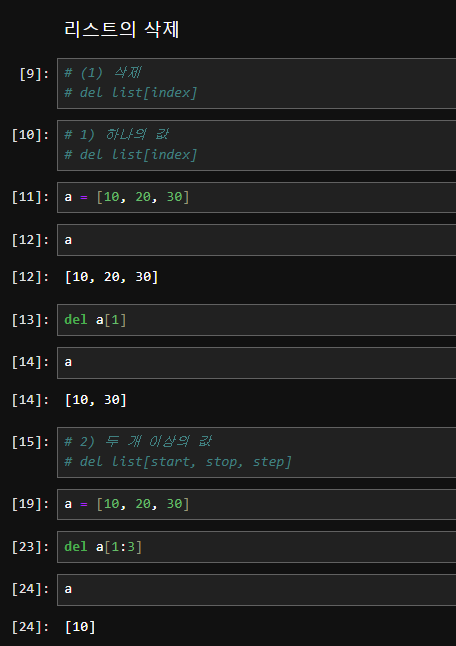
리스트 요소 삭제 my_list = [1, 15, 20, 3, 4, 5, 6, 7, 8, 9]
del 키워드를 사용하여 특정 인덱스의 요소를 삭제할 수 있습니다.
remove() 메서드를 사용하여 특정 값을 가진 요소를 삭제할 수 있습니다.
** 주의) 특정 요소에 해당하는 값이 여러개 있을 경우에는,
첫 번째만 삭제 됨. (그런데 왜,,, 아래 연습엔...)

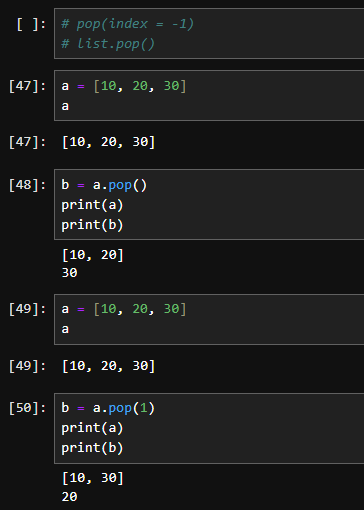
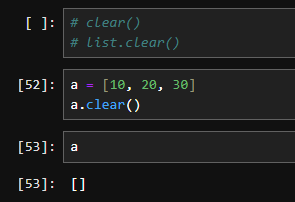
pop() 메서드를 사용하여 특정 인덱스의 요소를 꺼내고 삭제할 수 있습니다.
리스트 길이 my_list = [1, 3, 5, 6, 7, 8, 9]
len() 함수를 사용하여 리스트의 길이를 알 수 있습니다.
리스트 정렬 my_list = [1, 3, 5, 6, 7, 8, 9]
sort() 메서드를 사용하여 리스트를 정렬할 수 있습니다.
내림차순으로 정렬하려면 reverse=True 인자를 사용합니다.
리스트 뒤집기 my_list =
reverse() 메서드를 사용하여 리스트를 뒤집을 수 있습니다.
리스트에서 요소 찾기 my_list =
index() 메서드를 사용하여 특정 요소의 인덱스를 찾을 수 있습니다.
이러한 기본 연산들을 사용하면 리스트를 쉽게 조작하고 원하는 작업을 수행할 수 있습니다.
2. 튜플 (tuple)
- 정의: 순서가 있는 변경 불가능한 배열입니다.
- 특징:
- 소괄호 ()로 정의합니다.
- 다양한 데이터 유형을 포함할 수 있습니다.
- 요소를 추가, 삭제, 변경할 수 없습니다.
- 예시
my_tuple = (1, 2, 3, "a", "b", "c")
Python의 튜플(tuple)의 연산과 함수에 대해 알아보면,
튜플(tuple)은 변경할 수 없는 순서가 있는 컬렉션입니다. 튜플은 리스트와 비슷하지만, 수정이 불가능하다는 점에서 다릅니다. 튜플에서 사용할 수 있는 연산과 함수는 다음과 같습니다.
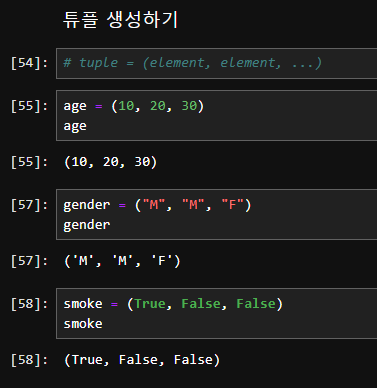
튜플의 생성
튜플은 소괄호 ()를 사용하여 생성합니다.
단일 요소를 가진 튜플을 생성할 때는 요소 뒤에 쉼표 ,를 추가해야 합니다.
튜플의 연산
튜플은 몇 가지 기본 연산을 지원합니다.

- 인덱싱 (Indexing): 튜플의 특정 요소에 접근할 수 있습니다.
python
print(my_tuple[0]) # 출력: 1 print(my_tuple[-1]) # 출력: 5 - 슬라이싱 (Slicing): 튜플의 일부를 추출할 수 있습니다.
python
print(my_tuple[1:3]) # 출력: (2, 3)
print(my_tuple[:2]) # 출력: (1, 2)
print(my_tuple[3:]) # 출력: (4, 5)
print(my_tuple[:]) # 출력: (1, 2, 3, 4, 5)
print(my_tuple[-2:]) # 출력: (4, 5)
print(my_tuple[::-1]) # 출력: (5, 4, 3, 2, 1) # 튜플 뒤집기 - 덧셈 (Concatenation): 두 튜플을 결합할 수 있습니다.
pythonnew_tuple = my_tuple + (6, 7)
print(new_tuple) # 출력: (1, 2, 3, 4, 5, 6, 7) - 반복 (Repetition): 튜플을 반복할 수 있습니다.
python
repeated_tuple = my_tuple * 2
print(repeated_tuple) # 출력: (1, 2, 3, 4, 5, 1, 2, 3, 4, 5)

튜플의 함수
튜플에서 사용할 수 있는 기본 내장 함수들입니다.
- len(): 튜플의 길이를 반환합니다.
python
print(len(my_tuple)) # 출력: 5 - max(): 튜플에서 최대값을 반환합니다.
python
print(max(my_tuple)) # 출력: 5 - min(): 튜플에서 최소값을 반환합니다.
python
print(min(my_tuple)) # 출력: 1 - sum(): 튜플 요소들의 합을 반환합니다.
python
print(sum(my_tuple)) # 출력: 15 - tuple(): 다른 데이터 타입을 튜플로 변환합니다.
python
my_list = [1, 2, 3]
my_tuple = tuple(my_list)
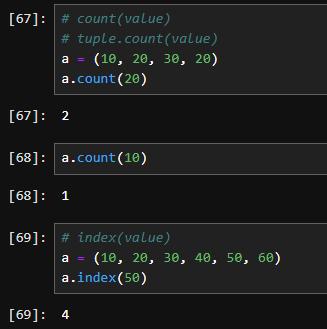
print(my_tuple) # 출력: (1, 2, 3) - index(): 튜플에서 특정 요소의 인덱스를 반환합니다. 해당 요소가 없으면 ValueError가 발생합니다.
pythonprint(my_tuple.index(3)) # 출력: 2
- count(): 튜플에서 특정 요소의 개수를 반환합니다.
python
print(my_tuple.count(2)) # 출력: 1
예시
튜플의 연산과 함수를 종합한 예시입니다.
my_tuple = (1, 2, 3, 4, 5)
# 인덱싱
print(my_tuple[0]) # 출력: 1
print(my_tuple[-1]) # 출력: 5
# 슬라이싱
print(my_tuple[1:3]) # 출력: (2, 3)
# 덧셈
new_tuple = my_tuple + (6, 7)
print(new_tuple) # 출력: (1, 2, 3, 4, 5, 6, 7)
# 반복
repeated_tuple = my_tuple * 2
print(repeated_tuple) # 출력: (1, 2, 3, 4, 5, 1, 2, 3, 4, 5)
# 함수 사용
print(len(my_tuple)) # 출력: 5
print(max(my_tuple)) # 출력: 5
print(min(my_tuple)) # 출력: 1
print(sum(my_tuple)) # 출력: 15
print(my_tuple.index(3)) # 출력: 2
print(my_tuple.count(2)) # 출력: 1
이렇게 튜플은 기본적인 연산과 함수를 제공하여 데이터를 효과적으로 다룰 수 있게 합니다. 단, 튜플은 불변(immutable)하기 때문에 한 번 생성된 후에는 수정할 수 없다는 점을 유념해야 합니다
3. 딕셔너리 (dictionary)
- 정의: 키-값 쌍의 집합입니다.
- 특징:
- 중괄호 {}로 정의합니다.
- 키는 고유해야 하며, 변경 불가능한 타입이어야 합니다(예: 문자열, 숫자, 튜플).
- 값은 변경 가능합니다.
- 예시:
my_dict = {"name": "Alice", "age": 25}
my_dict["age"] = 26 # {"name": "Alice", "age": 26}
Python의 딕셔너리 (dictionary)에 대해 알아보면,
Python의 딕셔너리(dictionary)는 키-값(key-value) 쌍으로 데이터를 저장하는 자료형입니다. 딕셔너리는 순서가 없고, 변경 가능하며, 중복된 키를 허용하지 않습니다. 각 키는 고유하며, 해당 키를 사용하여 값을 빠르게 검색할 수 있습니다.
딕셔너리의 생성 및 기본 사용법
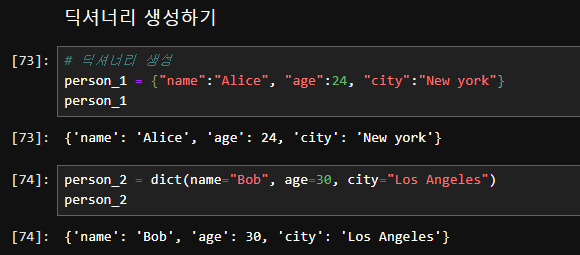
1. 딕셔너리 생성
- 중괄호 {}를 사용하거나 dict() 함수를 사용하여 딕셔너리를 생성할 수 있습니다.
another_dict = dict(name="Bob", age=30, city="Los Angeles")
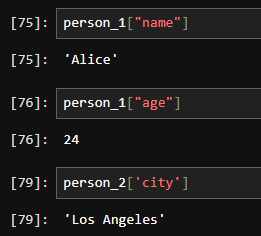
2. 딕셔너리 요소 접근
- 키를 사용하여 값에 접근할 수 있습니다.
print(my_dict["age"]) # 출력: 24
3. 딕셔너리 요소 추가 및 수정
- 키를 사용하여 값을 추가하거나 수정할 수 있습니다.
my_dict["email"] = "alice@example.com" # 새 키-값 쌍 추가
my_dict["age"] = 26 # 기존 값 수정
print(my_dict)

4. 딕셔너리 요소 삭제
- del 키워드 또는 pop() 메서드를 사용하여 요소를 삭제할 수 있습니다.
del my_dict["city"] # 키 "city"를 가진 요소 삭제
print(my_dict)

age = my_dict.pop("age") # 키 "age"를 가진 요소 삭제 및 값 반환
print(age)
print(my_dict)

> 변수 선언 누락 시, 오류 발생
해결 방법: 변수를 사용하기 전에 반드시 선언합니다.
person_1 = {'name': 'Alice', 'age': 26, 'email': 'alice@example.com'}
age = person_1.pop('age')
print(person_1)
print(age)
딕셔너리 매서드
1. keys(): 딕셔너리의 모든 키를 반환합니다.
print(my_dict.keys()) # dict_keys(['name', 'email'])
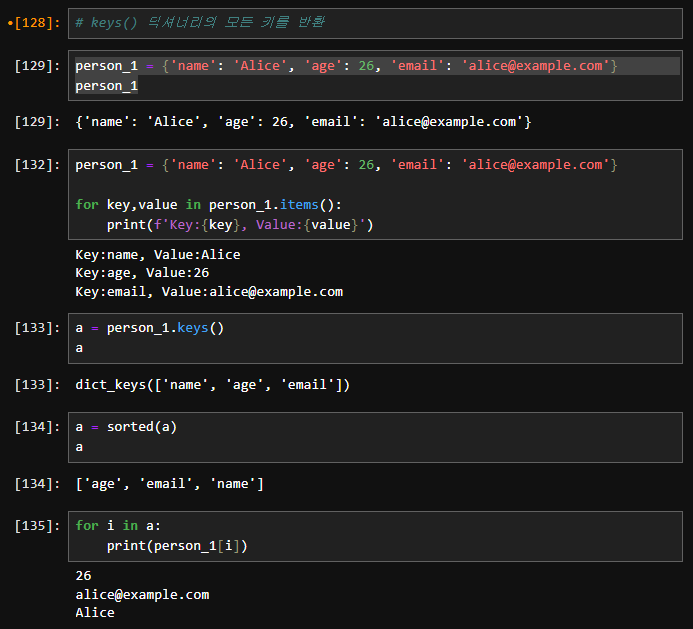
2. values(): 딕셔너리의 모든 값을 반환합니다.
print(my_dict.values()) # dict_values(['Alice', 'alice@example.com'])

3. items(): 딕셔너리의 모든 키-값 쌍을 반환합니다.
print(my_dict.items()) # dict_items([('name', 'Alice'), ('email', 'alice@example.com')])
============
딕셔너리의 items() 메서드는 딕셔너리의 모든 키-값 쌍을 반환합니다. 이 메서드는 딕셔너리의 모든 키와 값을 tuple 형태로 반환하며, 반환된 결과는 dict_items 객체로, 이는 반복(iterate) 가능하며 리스트와 유사한 객체입니다.
items() 메서드 사용 예시
다음은 items() 메서드를 사용하는 몇 가지 예시입니다:
1. items() 메서드 기본 사용법
# 딕셔너리 정의
person_1 = {'name': 'Alice', 'age': 25, 'city': 'New York'}
# items() 메서드를 사용하여 키-값 쌍을 얻기
items = person_1.items()
# items 출력
print(items) # 출력: dict_items([('name', 'Alice'), ('age', 25), ('city', 'New York')])
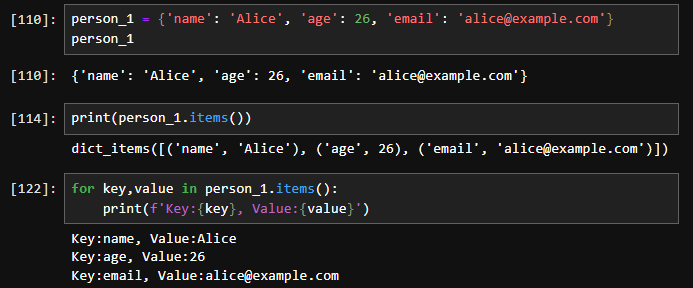
2. items() 메서드와 반복문 사용items() 메서드를 사용하여 딕셔너리의 모든 키와 값을 반복문을 통해 접근할 수 있습니다.
# 딕셔너리 정의
person_1 = {'name': 'Alice', 'age': 25, 'city': 'New York'}
# items() 메서드를 사용하여 반복문으로 키-값 쌍을 출력
for key, value in person_1.items():
print(f"Key: {key}, Value: {value}")
출력:
Key: name, Value: Alice
Key: age, Value: 25
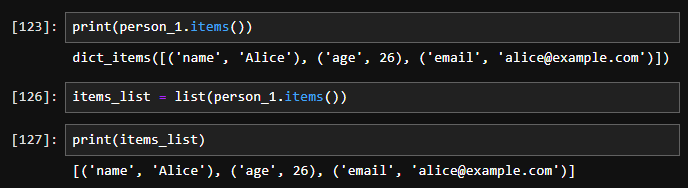
Key: city, Value: New York3. items() 메서드를 사용하여 키-값 쌍으로 리스트 변환
items() 메서드의 결과를 리스트로 변환할 수 있습니다.
# 딕셔너리 정의
person_1 = {'name': 'Alice', 'age': 25, 'city': 'New York'}
# items() 메서드를 사용하여 리스트로 변환
items_list = list(person_1.items())
# 리스트 출력
print(items_list) # 출력: [('name', 'Alice'), ('age', 25), ('city', 'New York')]
< 요약 >
- 기본 사용법: items() 메서드는 딕셔너리의 키-값 쌍을 튜플로 반환하는 dict_items 객체를 반환합니다.
- 반복문과 함께 사용: items() 메서드는 딕셔너리의 키-값 쌍을 반복문을 통해 쉽게 접근할 수 있도록 도와줍니다.
- 리스트로 변환: items() 메서드의 결과를 리스트로 변환하여 사용할 수도 있습니다.
items() 메서드를 사용하면 딕셔너리의 키와 값을 쉽게 다룰 수 있어 다양한 작업을 효율적으로 수행할 수 있습니다.

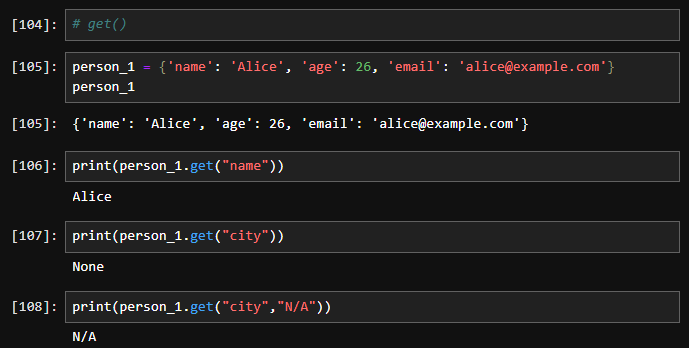
4. get(): 키를 사용하여 값을 반환합니다. 키가 존재하지 않으면 None 또는 지정된 기본값을 반환합니다.
print(my_dict.get("name")) # 출력: Alice
print(my_dict.get("age", "N/A")) # 출력: N/A (키 "age"가 없으므로 기본값 반환)
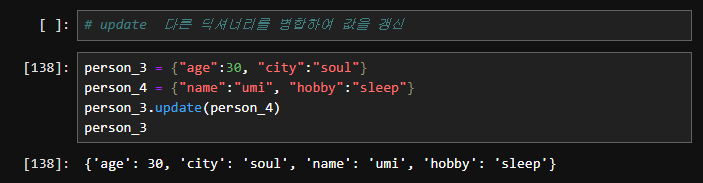
5. update(): 다른 딕셔너리를 병합하여 값을 갱신합니다.
my_dict.update({"age": 26, "city": "New York"})
print(my_dict)
6. clear(): 딕셔너리의 모든 요소를 삭제합니다.
my_dict.clear()
print(my_dict) # 출력: {}

예시
딕셔너리의 다양한 기능을 종합한 예시입니다.
# 딕셔너리 생성
my_dict = {"name": "Alice", "age": 25, "city": "New York"}

# 요소 접근
print(my_dict["name"]) # 출력: Alice
# 요소 추가 및 수정
my_dict["email"] = "alice@example.com"
my_dict["age"] = 26
print(my_dict)

# 요소 삭제
del my_dict["city"]
print(my_dict)
![del my_dict["city"]
print(my_dict)](https://blog.kakaocdn.net/dn/bnxfdT/btsH5AKTX4d/OBiA5eAMfZQsJN3FkNX221/img.png)
age = my_dict.pop("age")
print(age)
print(my_dict)

# 딕셔너리 메서드 사용
print(my_dict.keys()) # 출력: dict_keys(['name', 'email'])
print(my_dict.values()) # 출력: dict_values(['Alice', 'alice@example.com'])
print(my_dict.items()) # 출력: dict_items([('name', 'Alice'), ('email', 'alice@example.com')])

# get 메서드
print(my_dict.get("name")) # 출력: Alice
print(my_dict.get("city", "N/A")) # 출력: N/A

# update 메서드
my_dict.update({"age": 26, "city": "New York"})
print(my_dict)

# clear 메서드
my_dict.clear()
print(my_dict) # 출력: {}

요약
딕셔너리는 키-값 쌍으로 데이터를 저장하는 매우 유용한 자료형입니다. 키를 사용하여 빠르게 값을 검색할 수 있으며, 다양한 메서드를 통해 쉽게 조작할 수 있습니다. 딕셔너리는 데이터베이스의 레코드나 JSON 데이터와 같은 구조화된 데이터를 다룰 때 특히 유용합니다.
4. 시리즈 (Series)
- 정의: 1차원 배열과 유사한 데이터 구조로, 인덱스를 가지며 데이터는 순차적으로 저장됩니다.
- 특징:
- pandas 라이브러리에서 제공하는 자료구조입니다.
- 인덱스를 통해 데이터에 접근할 수 있습니다.
- 다양한 데이터 유형을 포함할 수 있습니다.
- 예시:
import pandas as pd
my_series = pd.Series([1, 2, 3, 4], index=["a", "b", "c", "d"])
Series는 파이썬의 데이터 분석 라이브러리인 pandas에서 제공하는 1차원 배열과 같은 자료 구조입니다. Series는 인덱스를 사용하여 데이터를 저장하며, 인덱스는 데이터의 위치를 나타내는 라벨입니다. 이는 고정된 길이의 순서가 있는 데이터 구조로, 리스트, 배열, 딕셔너리와 유사하지만, 더 많은 기능을 제공합니다.
Series의 특징
Series의 특징
- 인덱스: 각 데이터 요소는 고유한 인덱스를 가지며, 인덱스를 통해 데이터를 참조할 수 있습니다.
- 동일한 데이터 타입: Series는 동일한 데이터 타입의 값들로 구성됩니다.
- 데이터와 인덱스: Series는 값(value)과 인덱스(index)로 구성됩니다.

Series 생성 방법
Series는 pandas 라이브러리를 사용하여 생성할 수 있습니다. pandas는 일반적으로 pd라는 약어로 임포트합니다.
(pandas 라이브러리를 사용하려면 먼저 pandas를 임포트해야 합니다. 일반적으로 pandas는 pd라는 약어로 임포트됩니다.)
import pandas as pd
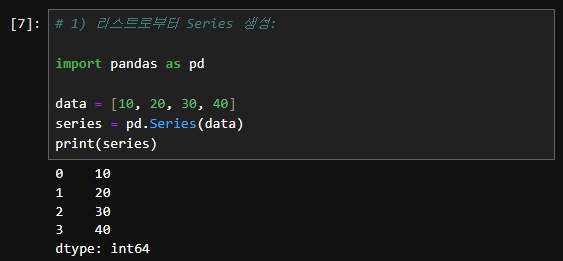
1. 리스트로부터 Series 생성:
data = [10, 20, 30, 40]
series = pd.Series(data)
print(series)
설명
- 인덱스: 0, 1, 2, 3은 Series의 기본 인덱스입니다. 리스트의 각 요소는 기본적으로 정수 인덱스를 가집니다.
- 값: 10, 20, 30, 40은 리스트 data의 요소들입니다.
- dtype: int64는 Series의 데이터 타입을 나타냅니다. 여기서는 정수형(int64)입니다.
Series의 기본 구성 요소
- 인덱스(index): 각 데이터 요소의 위치를 나타내며, 기본적으로 0부터 시작하는 정수 인덱스입니다. 인덱스는 사용자 정의로 설정할 수도 있습니다.
- 값(values): 실제 데이터 요소들입니다.
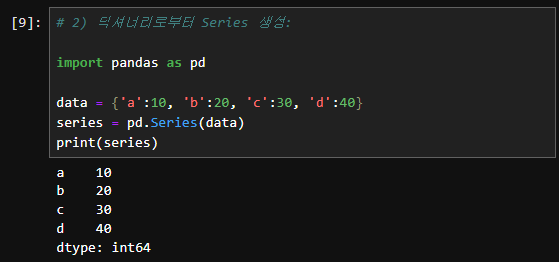
2. 딕셔너리로부터 Series 생성:
data = {'a': 10, 'b': 20, 'c': 30}
series = pd.Series(data)
print(series)
3. 인덱스를 지정하여 Series 생성:
data = [10, 20, 30, 40]
index = ['a', 'b', 'c', 'd']
series = pd.Series(data, index=index)
print(series)

< Series 사용 예시 >
> Series 생성 및 기본 사용
import pandas as pd
# 리스트로부터 Series 생성
data = [10, 20, 30, 40]
series = pd.Series(data)
print(series)
출력
0 10
1 20
2 30
3 40
dtype: int64
> 딕셔너리로부터 Series 생성
data = {'a': 10, 'b': 20, 'c': 30}
series = pd.Series(data)
print(series)
출력
a 10
b 20
c 30
dtype: int64
> 인덱스를 지정하여 Series 생성
data = [10, 20, 30, 40]
index = ['a', 'b', 'c', 'd']
series = pd.Series(data, index=index)
print(series)
출력
a 10
b 20
c 30
d 40
dtype: int64
Series의 기본 연산
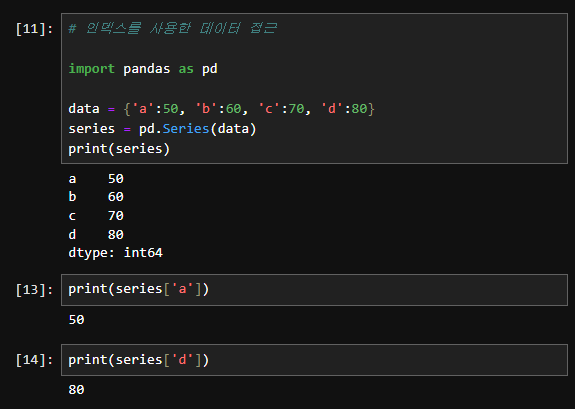
- 인덱스를 사용한 데이터 접근:
print(series['a']) # 출력: 50
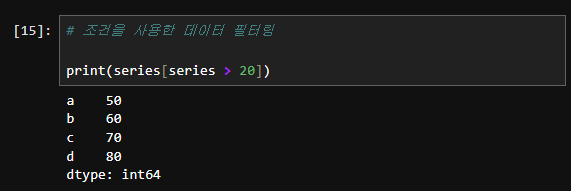
- 조건을 사용한 데이터 필터링:
print(series[series > 20]) # 출력: a 50, b 60, c 70, d 80
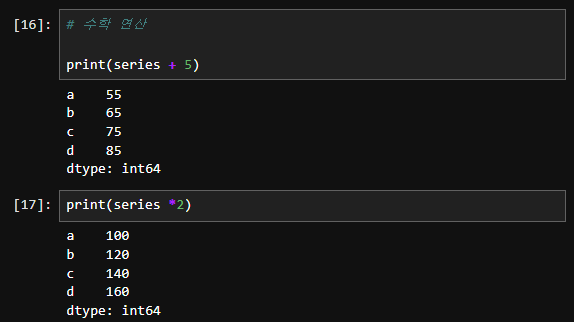
- 수학 연산:
print(series + 5) # 출력: a 55, b 65, c 75, d 85
print(series * 2) # 출력: a 100, b 120, c 140, d 160
Series의 유용한 메서드

- head(): 상위 n개의 데이터 반환 (기본값은 5개)
print(series.head(2)) # 출력: a 5, b 6

- tail(): 하위 n개의 데이터 반환 (기본값은 5개)
print(series.tail(2)) # 출력: c 7, d 8

- mean(): 평균값 계산
print(series.mean()) # 출력: 6.5

- sum(): 합계 계산
print(series.sum()) # 출력: 100

- unique(): 고유한 값 반환
print(series.unique()) # 출력: array([10, 20, 30, 40])

요약
Series는 pandas의 기본 데이터 구조 중 하나로, 1차원 배열과 유사합니다. 인덱스를 통해 데이터에 접근할 수 있으며, 다양한 연산과 메서드를 제공합니다. 데이터 분석 및 조작에 매우 유용한 도구로, pandas 라이브러리의 핵심 구성 요소입니다.
5. 데이터프레임 (DataFrame)
- 정의: 2차원 테이블 구조로, 여러 개의 시리즈가 모여서 행과 열을 이루는 구조입니다.
- 특징:
- pandas 라이브러리에서 제공하는 자료구조입니다.
- 각 열은 시리즈이며, 서로 다른 데이터 유형을 가질 수 있습니다.
- SQL 테이블이나 엑셀 스프레드시트와 유사합니다.
- 예시:
import pandas as pd
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
}
df = pd.DataFrame(data)
DataFrame은 파이썬의 데이터 분석 라이브러리인 pandas에서 제공하는 2차원, 테이블 형식의 자료 구조입니다. DataFrame은 행(row)과 열(column)로 구성되며, 각 열은 서로 다른 데이터 타입을 가질 수 있습니다. 이는 엑셀 스프레드시트나 SQL 테이블과 유사합니다. DataFrame은 데이터 분석 및 조작 작업에 매우 유용합니다.
DataFrame의 특징
- 2차원 구조: 행과 열로 구성됩니다.
- 다양한 데이터 타입: 각 열은 서로 다른 데이터 타입을 가질 수 있습니다.
- 레이블 인덱싱: 행과 열 모두 레이블 인덱싱을 지원합니다.
- 다양한 데이터 소스: 리스트, 딕셔너리, NumPy 배열, 외부 파일(CSV, Excel 등) 등 다양한 데이터 소스로부터 생성할 수 있습니다.
DataFrame 생성 방법
pandas를 사용하여 여러 가지 방법으로 DataFrame을 생성할 수 있습니다.
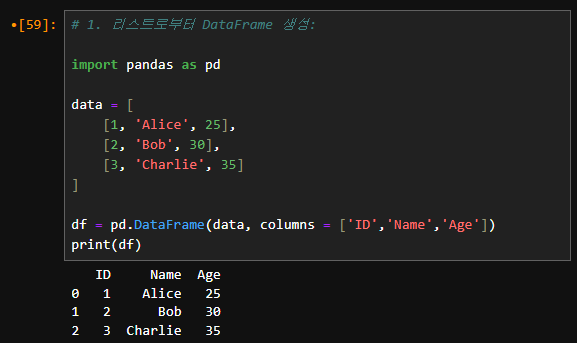
1. 리스트로부터 DataFrame 생성:
import pandas as pd
data = [
[1, 'Alice', 25],
[2, 'Bob', 30],
[3, 'Charlie', 35]
]
df = pd.DataFrame(data, columns=['ID', 'Name', 'Age'])
print(df)
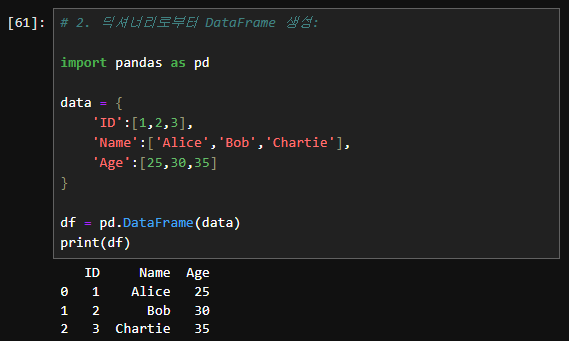
2. 딕셔너리로부터 DataFrame 생성:
data = {
'ID': [1, 2, 3],
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
df = pd.DataFrame(data)
print(df)
3. 외부 파일로부터 DataFrame 생성 (CSV 파일):
df = pd.read_csv('data.csv')
print(df)
1) 파일 경로 확인:
pd.read_csv() 함수에 전달한 파일 경로가 정확한지 확인하세요.
파일이 현재 작업 디렉토리에 있는지 확인하거나, 파일의 절대 경로를 사용하세요.
예를 들어, 파일이 'C:/data/data.csv'에 있다면:
df = pd.read_csv('C:/data/data.csv')
2) 현재 작업 디렉토리 확인:
- 현재 작업 디렉토리가 어디인지 확인하고, 파일이 해당 디렉토리에 있는지 확인하세요.
- 현재 작업 디렉토리는 다음 명령어로 확인할 수 있습니다.
import os
print(os.getcwd())
> 예시
다음은 파일이 'C:/data/data.csv'에 있다고 가정한 코드입니다.
import pandas as pd
# 절대 경로를 사용하여 CSV 파일 읽기
file_path = 'C:/data/data.csv'
df = pd.read_csv(file_path)
print(df)
현재 작업 디렉토리와 파일 확인
import os
# 현재 작업 디렉토리 확인
current_dir = os.getcwd()
print(f"현재 작업 디렉토리: {current_dir}")
# 파일이 현재 작업 디렉토리에 있는지 확인
file_name = 'data.csv'
file_path = os.path.join(current_dir, file_name)
if os.path.exists(file_path):
print (f"파일이 존재합니다: {file_path}")
df = pd.read_csv(file_path)
print(df)
else:
print(f"파일이 존재하지 않습니다: {file_path}")

DataFrame 사용 예시
DataFrame 생성 및 기본 사용
import pandas as pd
# 딕셔너리로부터 DataFrame 생성
data = {
'ID': [1, 2, 3],
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
df = pd.DataFrame(data)
print(df)
출력
ID Name Age
0 1 Alice 25
1 2 Bob 30
2 3 Charlie 35
행과 열 접근
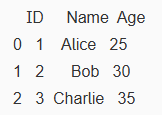
- 열 접근:
print(df['Name']) # 특정 열 접근
![print(df[&#39;Name&#39;]) # 특정 열 접근](https://blog.kakaocdn.net/dn/d1B630/btsH5VaGpNC/GkaiuO0x24vZKP57OUL0w0/img.png)
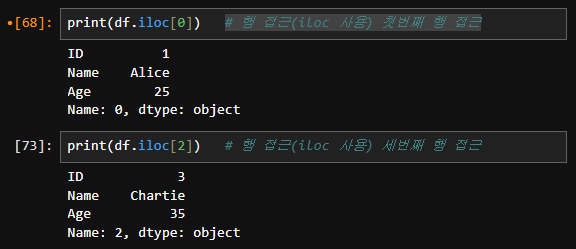
- 행 접근 (iloc 사용):
print(df.iloc[0]) # 첫 번째 행 접근
print(df.iloc[2]) # 세 번째 행 접근
- 행과 열 동시 접근:
print(df.loc[0, 'Name']) # 첫 번째 행의 'Name' 열 값 접근
![print(df.loc[0&#44; &#39;Name&#39;]) # 첫 번째 행의 &#39;Name&#39; 열 값 접근](https://blog.kakaocdn.net/dn/cLNur7/btsH4L8dpeH/3M7K1K102kfL3hWitEKwE1/img.png)
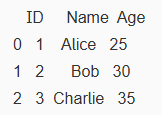
DataFrame 기본 연산 및 메서드
- 통계 정보 요약:
print(df.describe()) # 기본 통계 정보 요약
- 데이터 필터링:
print(df[df['Age'] > 25]) # 'Age'가 25보다 큰 행 필터링
![print(df[df['Age'] > 25]) # 'Age'가 25보다 큰 행 필터링](https://blog.kakaocdn.net/dn/cbGD8n/btsH4BdGo7a/brjKGQrWT9c3raIoOmqqRK/img.png)
- 새로운 열 추가:
df['Salary'] = [50000, 60000, 70000]
print(df)

![새로운 열 추가: df[&#39;Salary&#39;] = [50000&#44; 60000&#44; 70000] print(df)](https://blog.kakaocdn.net/dn/OJYnj/btsH6ujpGc7/Usmy7Hp1dhjrKNYe6WrkoK/img.png)
- 기존 열 수정:
df['Age'] = df['Age'] + 1
print(df)
![기존 열 수정:
df['Age'] = df['Age'] + 1
print(df)](https://blog.kakaocdn.net/dn/ng1zS/btsH5ICGfjs/3Y4fpCRLyp12RcNVLE8Km1/img.png)
요약
- DataFrame은 2차원 테이블 형식의 데이터 구조로, 행과 열로 구성됩니다.
- 다양한 데이터 소스(리스트, 딕셔너리, 외부 파일 등)로부터 생성할 수 있습니다.
- 행과 열을 통해 데이터를 쉽게 접근하고 조작할 수 있습니다.
- 기본적인 통계 정보 요약, 데이터 필터링, 열 추가 및 수정 등의 기능을 제공합니다.
DataFrame은 데이터 분석과 조작에 매우 강력한 도구이며, pandas 라이브러리의 핵심 구성 요소 중 하나입니다.
이 데이터 구조들은 각각의 용도와 상황에 맞게 적절히 선택하여 사용하면 효율적으로 데이터를 처리하고 분석할 수 있습니다. pandas 라이브러리는 데이터 분석을 위한 강력한 도구이며, 시리즈와 데이터프레임은 그 핵심 구성 요소입니다.
'python, anaconda study' 카테고리의 다른 글
| "Python 4) Anaconda prompt ; DataFrame 연습문제 (2)" (0) | 2024.06.22 |
|---|---|
| "Python 4) Anaconda prompt ; DataFrame 연습문제 (1)" (0) | 2024.06.22 |
| "Python 2) Anaconda prompt 연산자 (산술, 비교, 논리, 비트, 식별 ...)" (0) | 2024.06.18 |
| "Python 1) Anaconda prompt 명령어 (dir / tree / cd / 드라이브 / md / rd ?" (2) | 2024.06.18 |



